

相關(guān)服務(wù)
載體構(gòu)建質(zhì)粒DNA制備
病毒包裝服務(wù)
mRNA基因遞送解決方案
CRISPR基因編輯解決方案
shRNA基因敲低解決方案

Determining how similar or different two sequences are to each other is a common approach for inferring structural, functional or evolutionary relationships between two sequences. VectorBuilder’s Sequence Alignment tool allows you to not only directly compare two sequences at the DNA or protein level, but also compare two DNA sequences based on translation.
Alignment provides a global perspective with percent identity/similarity across entire sequences and a focused perspective comparing individual nucleotides/amino acids. This tool utilizes gaps and gap penalties to maximize the chances of matching two nucleotides or amino acids while maintaining data integrity. While gaps account for insertions or deletions in the aligned sequences, gap penalties assign negative scores to the alignment based on the frequency and length of the gaps.
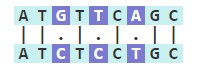
When studying differences between genes, proteins, or organisms, sequence alignments can help to predict structural relationships, functions, and evolutionary changes. Two or more DNA or protein sequences can be compared for similarity at the local and global level. Each sequence is compared nucleotide by nucleotide, and matches are highlighted and designated with bar symbols. In the sequence below, there is 67% similarity (6/9 nucleotides), with total 3 total mismatches (Hamming distance).
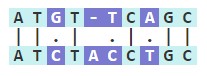
However, aligning sequences is often complicated by the presence of substitutions as well as indels (insertions and deletions). Alignment algorithms can account for these events with gaps, where a space (-) can be placed to optimize alignment. In the sequence below, there is slightly lower similarity (60%) due to the insertion in the second sequence. The percent similarity only takes into account matches, not whether there is a mismatch, a gap, or part of an extended gap.
With larger and more complex sequence comparisons, it quickly becomes untenable to perform alignments by hand. The algorithm used in VectorBuilder’s Sequence Alignment tool determines the best alignment by optimizing the alignment score, which takes into account matches, mismatches, gaps, and extended gaps with individual scores for each event at each nucleotide.
Once you have the alignment for your sequences, you can examine the alignment score, the length of the alignment (how many total nucleotides matching), and the locations of high similarity. Aligning DNA from two different species can help determine more homologous regions and/or regions under higher selective pressure. When aligning a protein sequence with that of a well-characterized protein, you can predict secondary structures as well as function.
Bridging the gap between the DNA and protein sequence can be extremely valuable in cloning efforts, particularly when cloning a gene in another species (heterologous expression). Changing the DNA sequence may or may not change the resultant protein sequence, because of redundancy in the genetic code. Most amino acids are coded by more than one codon sequence (Figure 1), so a mutation that changes GGA to GGC will still produce glycine.
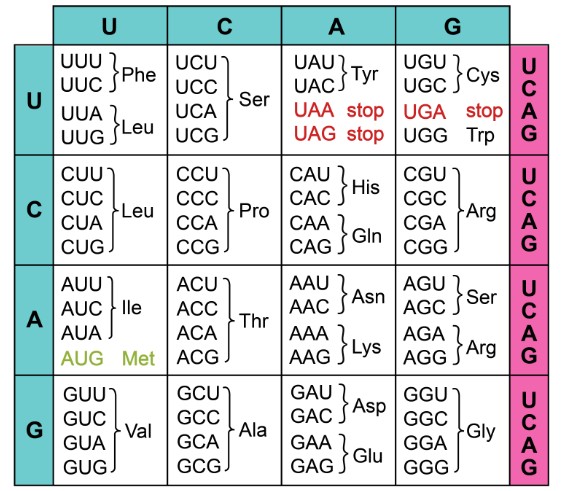
Figure 1. Each three-letter nucleotide sequence corresponds to an amino acid or direction (start/stop).
To determine how DNA alignment translates to protein alignment, VectorBuilder offers an option to align based on translated DNA. Below, the Sox2 coding sequences in mouse and human are aligned. These sequences exhibit about 93% similarity (Figure 2A).
However, when the same sequences are used to view similarity of the translated protein (by selecting “DNA alignment based on translated protein sequence”), the resultant alignment shows 97% similarity, highlighting mutations to base pairs that have not influenced protein sequence or function (Figure 2B). Determining the similarity/difference between DNA or protein sequences as well as translated DNA sequences provides a powerful tool for examining relationships between proteins or organisms.

A

B
Figure 2. Alignment between coding sequences for Sox2 in human and mouse (A), and alignment between translated amino acid sequences (B).