

相關(guān)服務(wù)
載體構(gòu)建質(zhì)粒DNA制備
病毒包裝服務(wù)
mRNA基因遞送解決方案
CRISPR基因編輯解決方案
shRNA基因敲低解決方案

Codon tables are the Rosetta Stone of molecular biology; they are a fundamental tool in enabling you to decipher the genetic code. The table below acts as a reference for how nucleotides translate into codons as well as unique species-specific preferences for individual codons. Codon optimization can be used on large-scale sequences, while this table can be used to analyze individual codons. You can clone codon-optimized sequences easily into vectors and order downstream services by clicking here.
The genetic code is a set of rules used by living cells to translate information encoded in the genetic material (DNA) in the form of genes into a particular protein. The process of genetic information transfer within cells involves transcription of DNA to messenger RNA (mRNA), which then gets translated and dictates the sequence of amino acids that make up the protein.
Each gene or mRNA encoding a protein contains a set of codons; codons are sequences of three nucleotides—a combination of adenine (A), thymine (T), cytosine (C), and guanine (G) in DNA, or A, C, G, and uracil (U) in mRNA. Since there are 4 nucleotides (A/T/G/C), there are 43, or 64, possible codons. Of these, 61 codons correspond to one of the 20 possible amino acids used in protein synthesis while the other 3 serve as stop signals, terminating protein synthesis. Given that there are 64 codons but only 20 unique amino acids, several amino acids are represented by multiple codons, reflecting redundancy in the genetic code. The order of these codons determines the sequence of amino acids in the resulting polypeptide chain and thus the eventual structure and function of the protein.
Once mRNA is transcribed from DNA within the nucleus of the cell, it moves to the cytoplasm. In eukaryotic cells, protein synthesis occurs at ribosomes, which are typically found in the cytoplasm or attached to the endoplasmic reticulum. A ribosome is composed of two subunits: the smaller subunit binds the mRNA template, while the larger subunit binds to transfer RNAs (tRNAs) that deliver amino acids to the forming polypeptide.
The translation process begins when the smaller ribosomal subunit attaches to the mRNA and starts scanning from the 5’ end of the mRNA to identify the start codon (AUG), signaling the start of protein synthesis. In the cytoplasm, tRNAs carry anticodons—sequences of three nucleotides that are complementary to the codon sequences on the mRNA. Each tRNA molecule is associated or “charged” with a specific amino acid that corresponds to its anticodon. Once the ribosome is correctly aligned at the start codon, the tRNA with the complementary anticodon (UAC for AUG) binds to the mRNA. As the mRNA continues to be read by the ribosome, it brings together amino acids carried by tRNAs and catalyzes the formation of peptide bonds between them. When a stop codon on mRNA is reached (UAA, UAG, or UGA), this signals the end of translation, and the completed polypeptide is released.
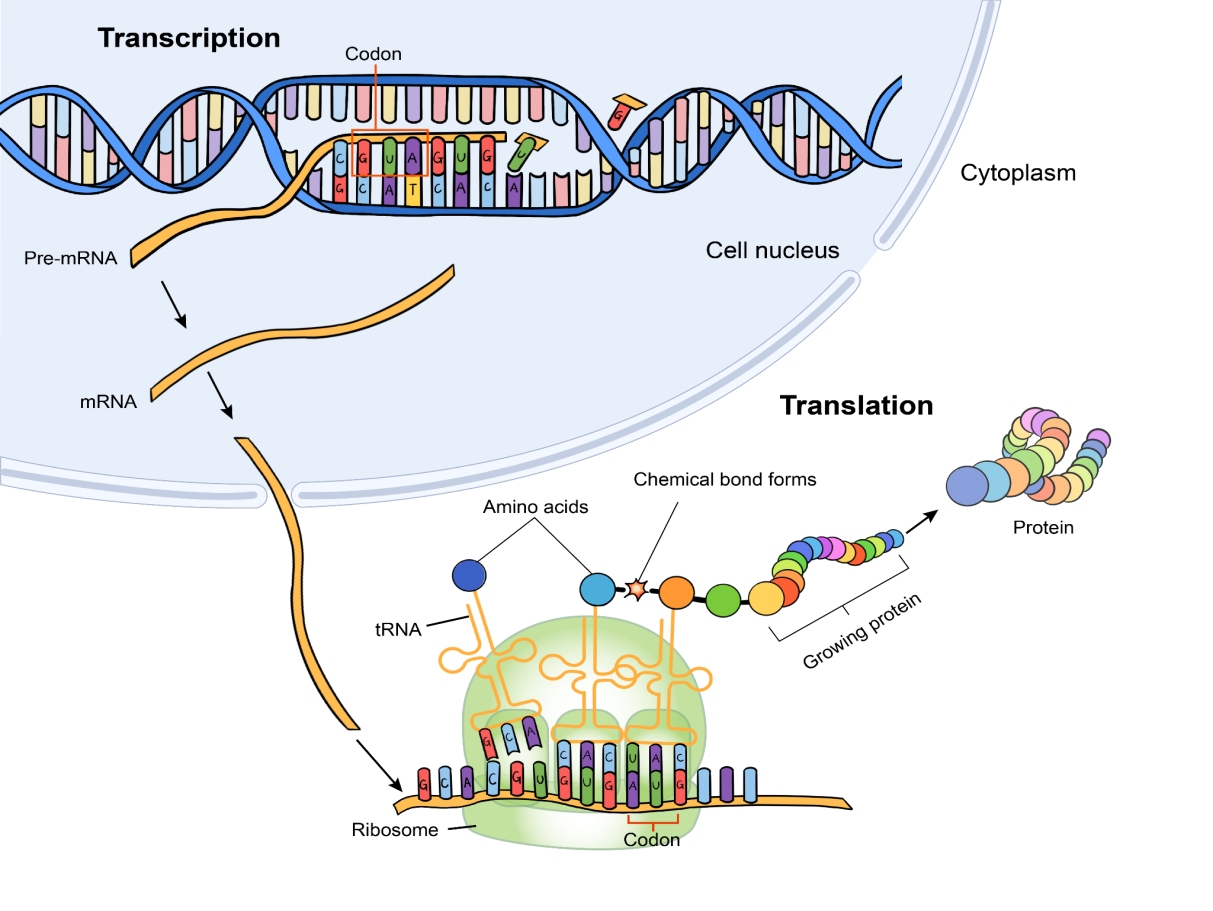
Figure 1. Protein translation
Despite multiple codons encoding the same amino acid, organisms often tend to show a preference for using specific codons over others, a phenomenon known as codon bias. This preference can vary significantly between different organisms, tissues within an organism, or even among genes within the same genome. For example, E. coli prefers the codon ‘GAA’ for encoding the amino acid glutamic acid (Glu), whereas human cells might prefer the synonymous codon ‘GAG’ for the same amino acid. Several factors may contribute to codon bias, including abundance of tRNAs, random changes in allele frequencies, host cellular environment, or GC content of the genome.
It is therefore essential to “optimize” the codons for applications where efficient, high-level protein production is required, and it directly leverages the concept of codon bias to achieve better results. The Codon Adaptation Index (CAI) is a quantitative measure that evaluates how well given codons match with the biases of an organism, ranging from 0 to 1. A CAI of 1 reflects a coding sequence where all amino acids are translated from the most frequently used codons in that organism.
Our Codon Optimization tool presents a sequence that balances an optimal CAI with other factors that can influence molecular experiments.
For deeper analysis of your sequence, check out our Codon Optimization tool.
To translate your DNA sequence into amino acid sequences, use our DNA Translation tool.
To compare two sequences at the DNA or protein level, you can utilize our Sequence Alignment tool.